性能基准 · v0.9.0
MindQuantum 与八个量子框架同台对比。
同一套硬件、同一组电路、统一双精度。我们在所有框架上分别跑了随机电路模拟与端到端 QAOA,并覆盖 CPU 与单卡 NVIDIA V100 两种后端。下方四张图即为结果。
测试方法
硬件
Intel Xeon E5-2620 v3 @ 2.40 GHz
16 线程并开启 SIMD;GPU 测试使用单卡 NVIDIA V100。
测试工具
pytest-benchmark
记录每次运行的端到端墙钟时间,取多次迭代的中位数。
数值精度
双精度 FP64
TensorFlow Quantum 仅支持单精度 FP32,框架本身未提供双精度路径。
九个框架,一套环境。
所有框架均安装其当前稳定版本,使用相同的线程配置,并接收完全一致的电路定义。
- MindQuantum 0.9.0
- Qiskit 0.45.0
- ProjectQ 0.8.0
- PennyLane 0.33.0
- PyQpanda 3.8.0
- Qulacs 0.6.2
- TensorFlow Quantum 0.7.2
- Intel-QS 2.0.0-beta
- cuQuantum 23.10.0
01 / 底层模拟性能
随机电路演化,4 至 27 比特。
每个框架模拟同一条随机电路,门集合包含 X、Y、Z、H、CNOT、S、T、RX、RY、RZ、Rxx、Ryy、Rzz、SWAP 及其受控版本。比特数从 4 扩展到 27,使用 pytest-benchmark 计时,以对数坐标绘制中位数耗时随比特数的变化。
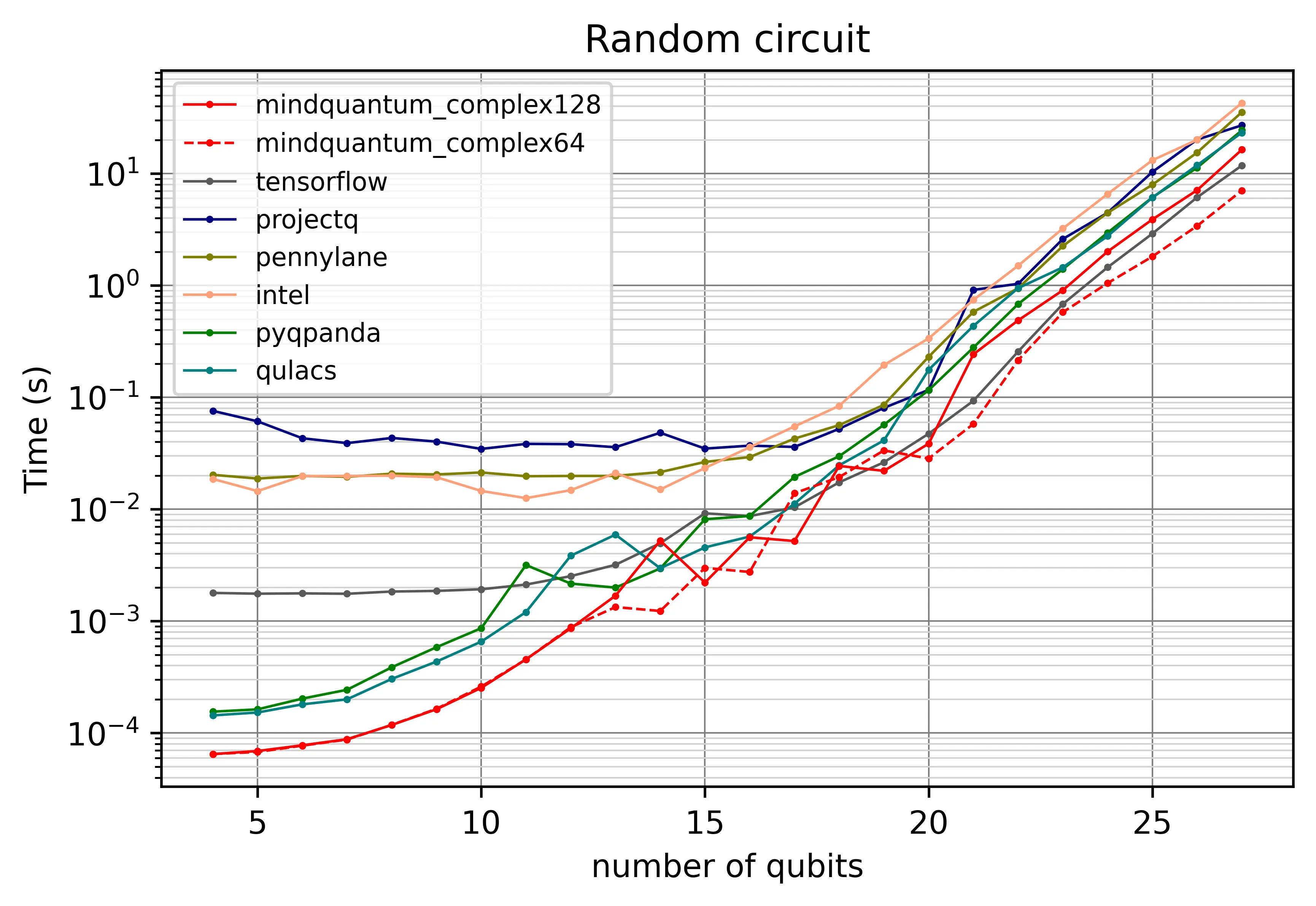
图 1a — CPU 后端
MindQuantum 与 Qulacs 在所有比特数下均处于领先。13 比特处的小幅下凹来自 MindQuantum 在该阈值切换到 OpenMP 多线程;阈值以下单线程更快。
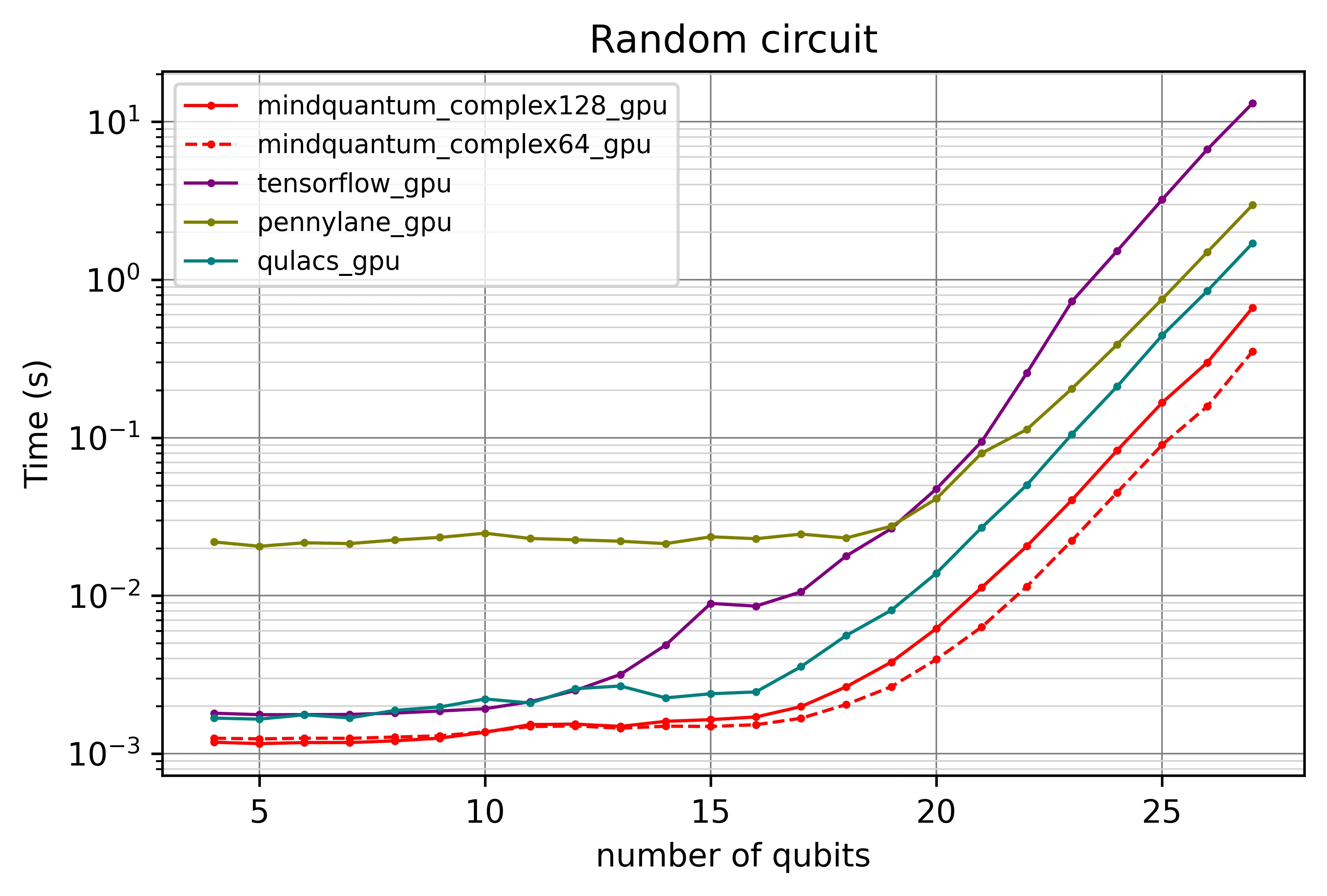
图 1b — GPU 后端
在单卡 V100 上,MindQuantum 一直保持领先直至 27 比特。TensorFlow Quantum 在高比特数下扩展更陡,但对比的是单精度对双精度。
MindQuantum 与 Qulacs 在底层实现上的优化已接近极限。
MindSpore Quantum 技术报告 · arXiv:2406.1724802 / 端到端优化
QAOA 在 4-正则图上的最大割求解。
对一个真实的变分工作负载进行端到端计时:用一阶 Trotter 分解构造 QAOA 拟设电路,再通过 scipy.optimize.minimize 的 BFGS 方法优化至收敛。问题规模从 5 个节点扩展到 23 个;各框架在自身时间预算耗尽时停止,因此曲线终止比特数不一致。
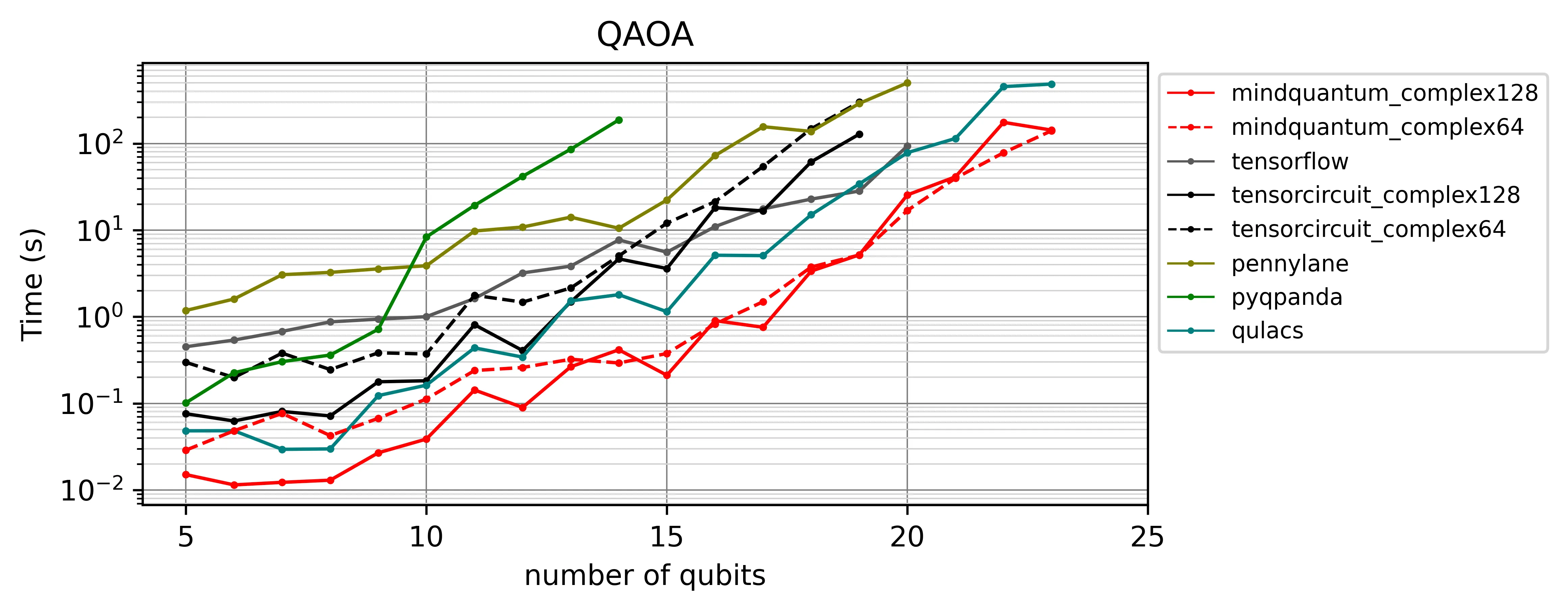
图 2a — CPU 后端
MindQuantum 在整个比特范围内至少领先一个数量级。缺少高效伴随方法的框架在早期就掉队。
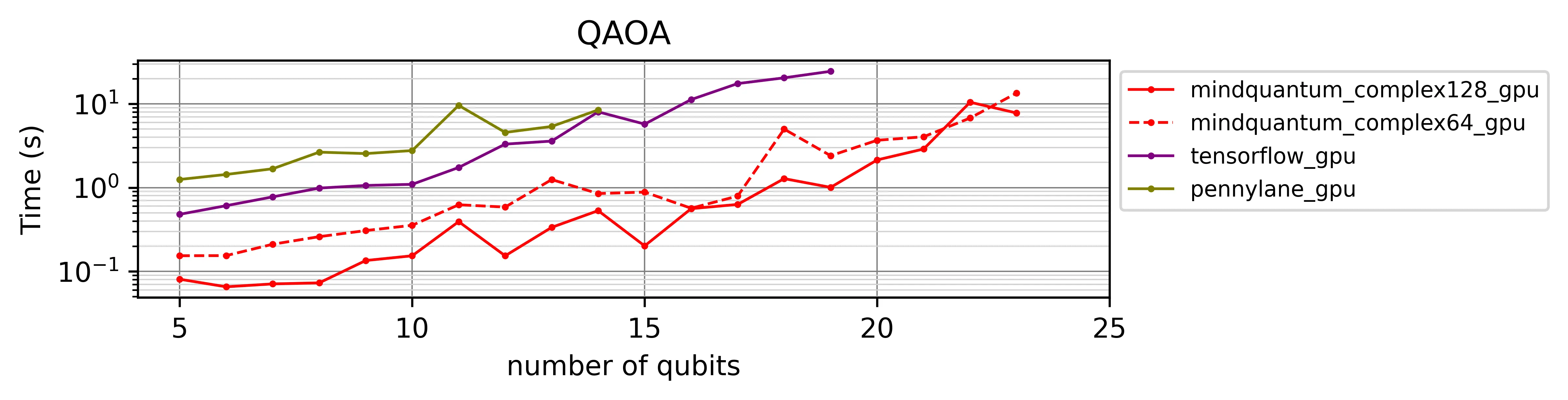
图 2b — GPU 后端
在 V100 上差距进一步拉大:PennyLane 在 14 比特处终止,TensorFlow Quantum 在 19 比特处终止,而 MindQuantum 跑到了 23 比特。
MindQuantum 至少比其他框架快一个数量级,这主要得益于其参数化电路梯度计算上经过优化的伴随方法与高效的电路演化实现。
MindSpore Quantum 技术报告 · arXiv:2406.17248复现这些基准。
本页所用的框架、电路与测试脚本均为开源代码。文中数据与文字摘自 MindSpore Quantum 技术报告;测试脚本与论文同仓库公开发布。