Performance benchmark · v0.9.0
MindQuantum against eight other quantum frameworks.
Same hardware, same circuits, double precision. We ran random circuit simulation and end-to-end QAOA on every framework, on both CPU and a single NVIDIA V100. The four charts below are the result.
Method
Hardware
Intel Xeon E5-2620 v3 @ 2.40 GHz
16 threads, SIMD enabled. NVIDIA V100 for the GPU runs.
Test harness
pytest-benchmark
End-to-end wall-clock per run. Each data point is the median of multiple iterations.
Numerical precision
Double (FP64)
TensorFlow Quantum is single precision (FP32); the framework does not expose a double-precision path.
Nine frameworks, one rig.
Every framework was installed at its current stable release, configured for the same number of threads, and given the same circuit definitions.
- MindQuantum 0.9.0
- Qiskit 0.45.0
- ProjectQ 0.8.0
- PennyLane 0.33.0
- PyQpanda 3.8.0
- Qulacs 0.6.2
- TensorFlow Quantum 0.7.2
- Intel-QS 2.0.0-beta
- cuQuantum 23.10.0
01 / Raw simulation speed
Random circuit evolution, 4 to 27 qubits.
Each framework simulates the same random circuit built from X, Y, Z, H, CNOT, S, T, RX, RY, RZ, Rxx, Ryy, Rzz, SWAP, and their controlled variants. Qubit count scales from 4 to 27. We time each run with pytest-benchmark and plot the median against the qubit count on a log scale.
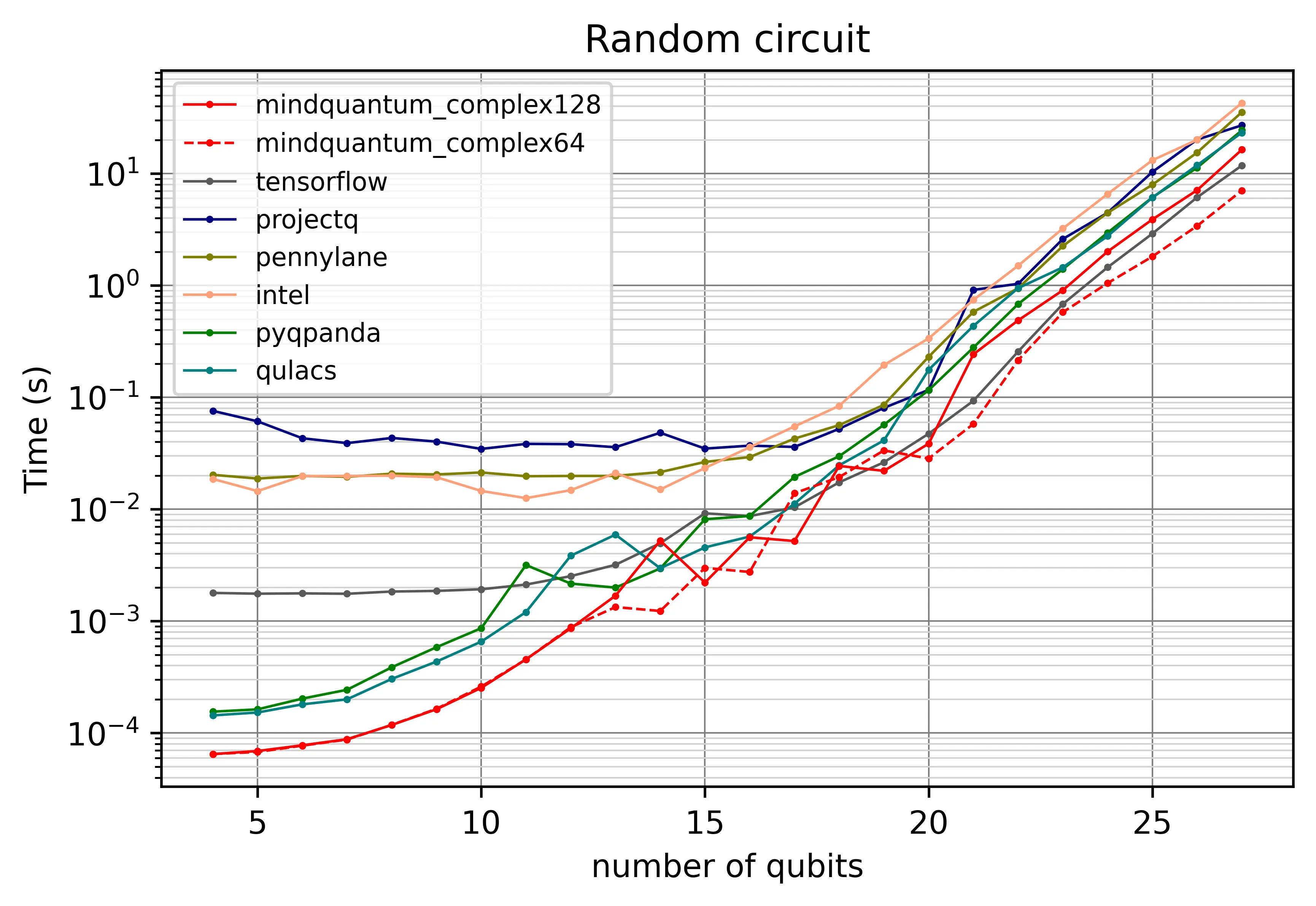
Fig. 1a — CPU backend
MindQuantum and Qulacs lead at every qubit count. The dip at 13 qubits is the threshold where MindQuantum switches on OpenMP multi-threading; below it the single-threaded path is faster.
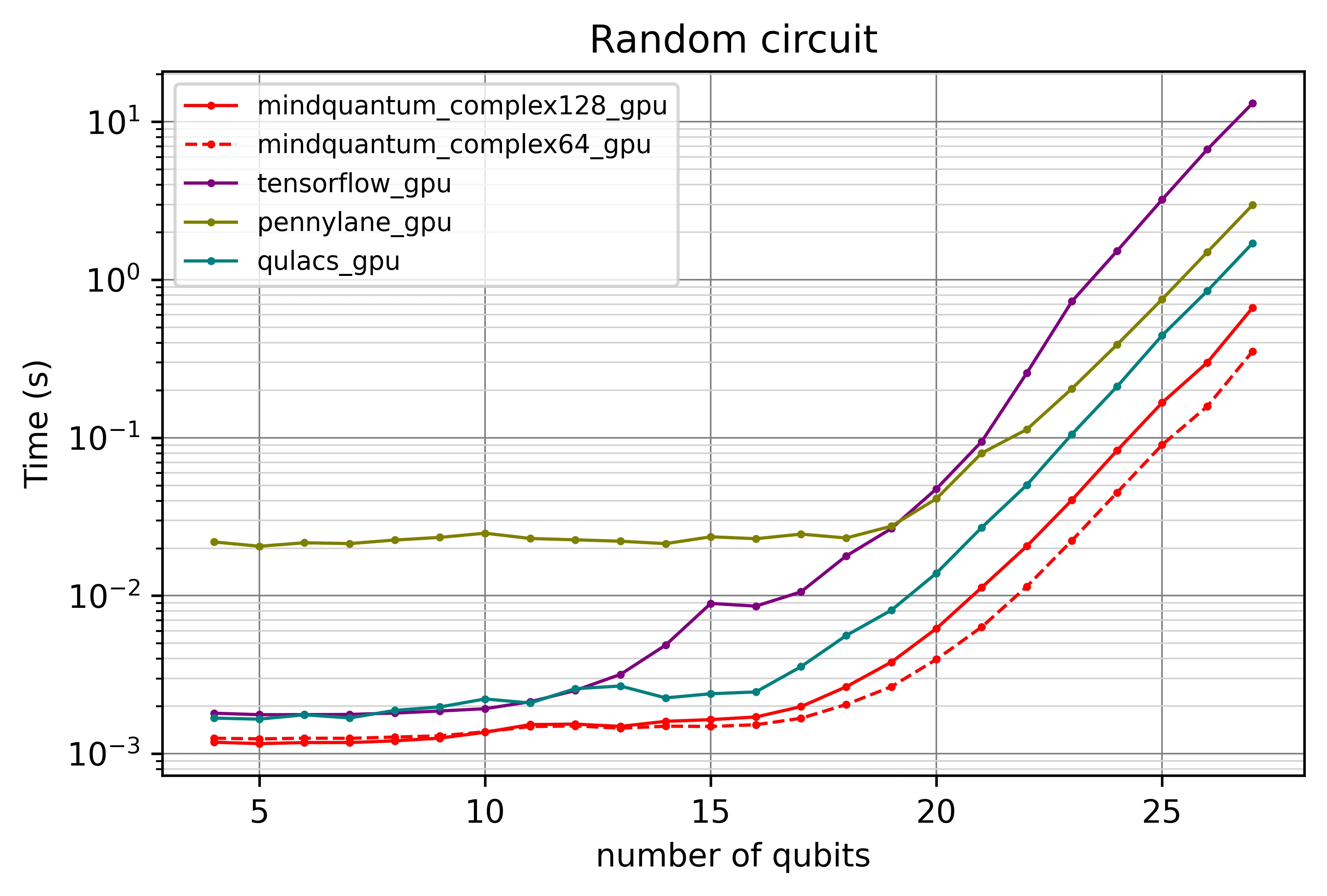
Fig. 1b — GPU backend
On a single V100, MindQuantum keeps its lead through 27 qubits. TensorFlow Quantum scales more aggressively at the high end, but the comparison is single precision against double.
MindQuantum and Qulacs have been optimized to near the limit of the low-level implementation.
MindSpore Quantum white paper · arXiv:2406.1724802 / End-to-end optimization
QAOA solving max-cut on 4-regular graphs.
End-to-end timing of a real variational workload: build the QAOA ansatz from a one-step Trotter decomposition, then drive it through scipy.optimize.minimize with BFGS until convergence. Problem size ranges from 5 to 23 nodes. Each framework runs until its own time budget is exhausted, which is why the curves end at different qubit counts.
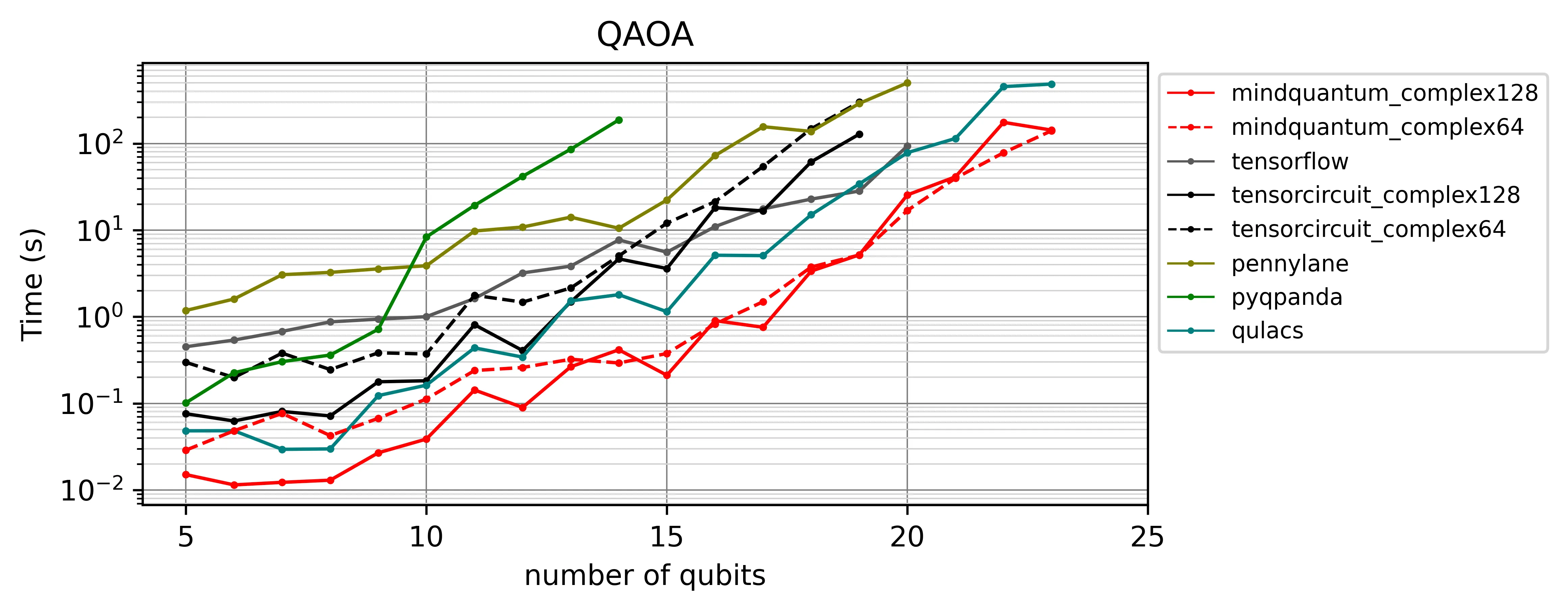
Fig. 2a — CPU backend
MindQuantum stays at least an order of magnitude ahead through the entire qubit range. Frameworks without an efficient adjoint method fall behind early.
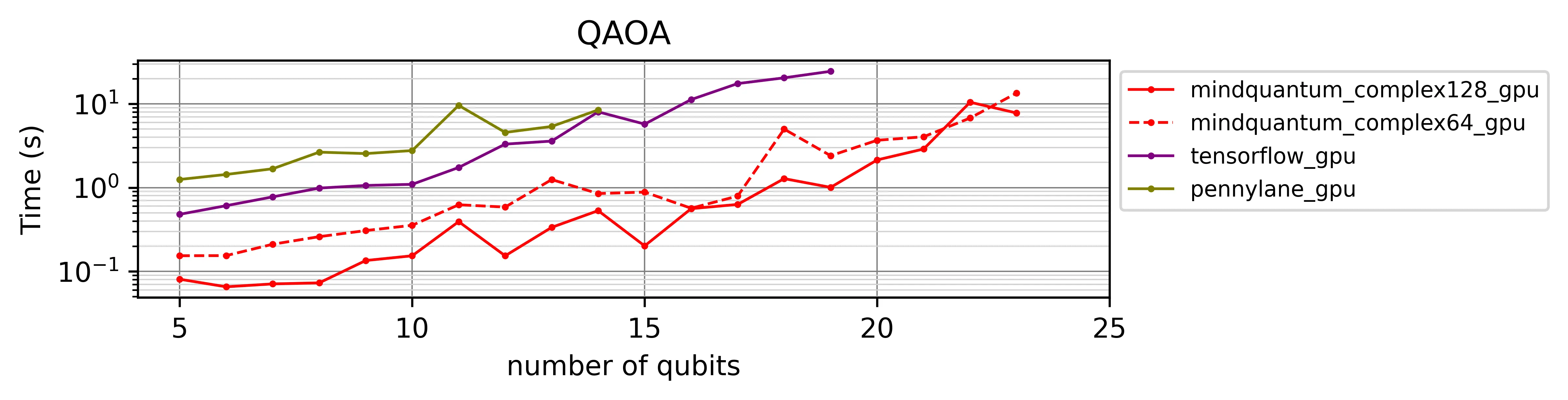
Fig. 2b — GPU backend
On the V100, the gap widens further. PennyLane drops out at 14 qubits, TensorFlow Quantum at 19; MindQuantum reaches 23.
MindQuantum is at least one order of magnitude faster than other frameworks, mainly due to its optimized adjoint method for gradient computation and efficient circuit evolution.
MindSpore Quantum white paper · arXiv:2406.17248Reproduce these benchmarks.
Every framework, circuit, and harness used here is open source. The text and figures on this page are drawn from the MindSpore Quantum white paper; the runner scripts live next to the paper in the public repository.